
C++ 重修之旅(一)

C++ 重修之旅(一)
CoolPine1 C++ 编译器的工作过程
当我们编写好了一些 C++ 代码(.cpp 文件)之后,就需要利用编译器将其变成机器可运行的二进制文件(.exe 文件)。
1.1 预处理
首先,编译器在收到 .cpp 文件后,会优先处理其中的预处理语句,即预处理发生在编译之前。一般来说,‘#’ 之后的都是预处理语句。
1.1.1 #include 语句
其中,最常用的预处理语句就是 #include <xxx>,其会将 xxx 文件中的所有内容复制粘贴到当前文件中。
头文件 endBrace.h 中的内容如下(只有一个右花括号):
1 | } |
而在 main.cpp 文件中的内容如下:
1 |
|
该程序虽然看着很奇怪,但可以正常编译并运行,其输出如下:
1 | hello |
1.1.2 #if 预处理语句
#if 预处理语句可以让我们包含或排除基于给定条件的代码。
新建 add.cpp 文件,其内容如下:
1 |
|
编译 add.cpp 后查看生成的 add.i 文件,内容如下:
1 |
|
修改 add.cpp 的内容:
1 |
|
重新编译,再查看 add.i 文件新生成的内容如下:
1 |
1.2 编译
然后,才开始进行编译。C++ 编译器将编译主要分为了编译和链接两个阶段。
若对整个项目进行编译 build,则编译器对于项目中的每一个 .cpp 文件都会生成一个后缀为 .obj 的目标文件。
在这一过程中,编译器会将 .cpp 文件视为一个翻译单元,根据这个翻译单元从而产生一个 .obj 文件。注意,此时文件本身的意义并不重要,即一个 .cpp 文件不一定等于一个翻译单元。
1.3 链接
通过编译生成的 .obj 文件之间是没有关联的,无法进行交互,如函数调用等,所以需要 Linker 对这些目标文件进行链接。 Linker 的基本功能就是将所有的 .obj 文件“黏合”到一起合并成一个.exe 可执行文件。
1.3.1 区分编译错误和链接错误
首先,要明确的是在 Visual Studio 中的错误列表 Error List 只能当作一个参考,如果需要更加具体的错误信息,还是需要查看输出 Output 窗口。 而如果在程序中出现了语法错误,在输出窗口中就会看见以 ‘error c…’ 开头的错误,表示该错误发生在编译阶段;如果出现了 ‘error LNK’ 开头的错误,则表示错误发生在链接阶段。
1.3.2 避免链接错误
static
add.cpp 中的内容如下:
1 | static int add(int a, int b) { |
在 add 函数定义之前加上 static,会意味着此处的 add 函数只被声明在 add.cpp 文件中,即无法从外部的文件,如 main.cpp 中调用 add 函数。
头文件监督
在 include 头文件时可能会由于多次引用相同的头文件而产生链接错误,为避免这种错误,有如下方法:
- 在头文件的第一行添加 #pragma once
- 利用 #ifndef、#define、#endif
2 基本语法
2.1 指针
指针对于管理和操纵内存十分重要。
在学习指针时,要先忘记指针的类型,明确所有类型的指针都是一个保存内存地址的整数。指针就像变量一样,但它不是像其他变量那样保存值本身,而是保存一个内存地址,但这个内存地址本身也是一个值、一个整数。
而指针的类型,只是说这个地址的数据为我们所给的类型,除此之外,指针的类型没有任何意义,类型的不同不会改变指针的值。
2.1.1 创建空指针
- void* ptr = 0;
- void* ptr = NULL;
- void* ptr = nullptr;
其中,NULL 是一种宏定义,即 #define NULL 0。而 nullptr 是 C++ 中的关键字。
2.1.2 在堆上创建数据
在写代码时,通常都是直接在栈上创建数据,如:
1 | int var = 8; |
我们也可以在堆上创建数据,即手动开辟内存:
1 |
|
其中,memset 的作用是使用指定的值来填充申请的内存块。其第一个参数是一个指针,即内存块开始的指针;第二个参数是填充值;第三个参数是填充的字节大小。
运行结果如下图所示: 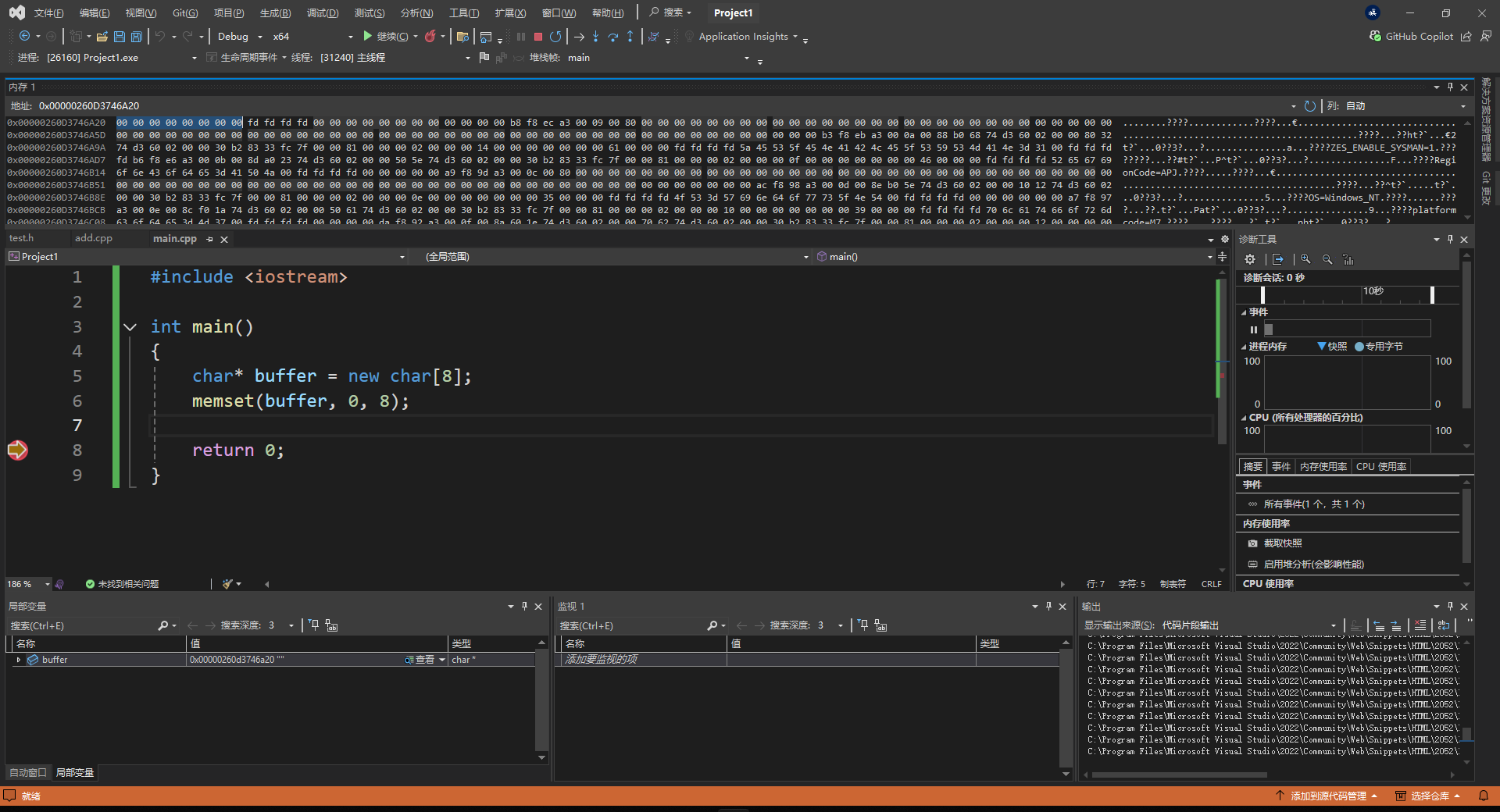
2.1.3 多级指针
由于指针本身也是变量,也存储在内存中,所以基于此可以得到指向指针的指针,指向指针的指针的指针…😵
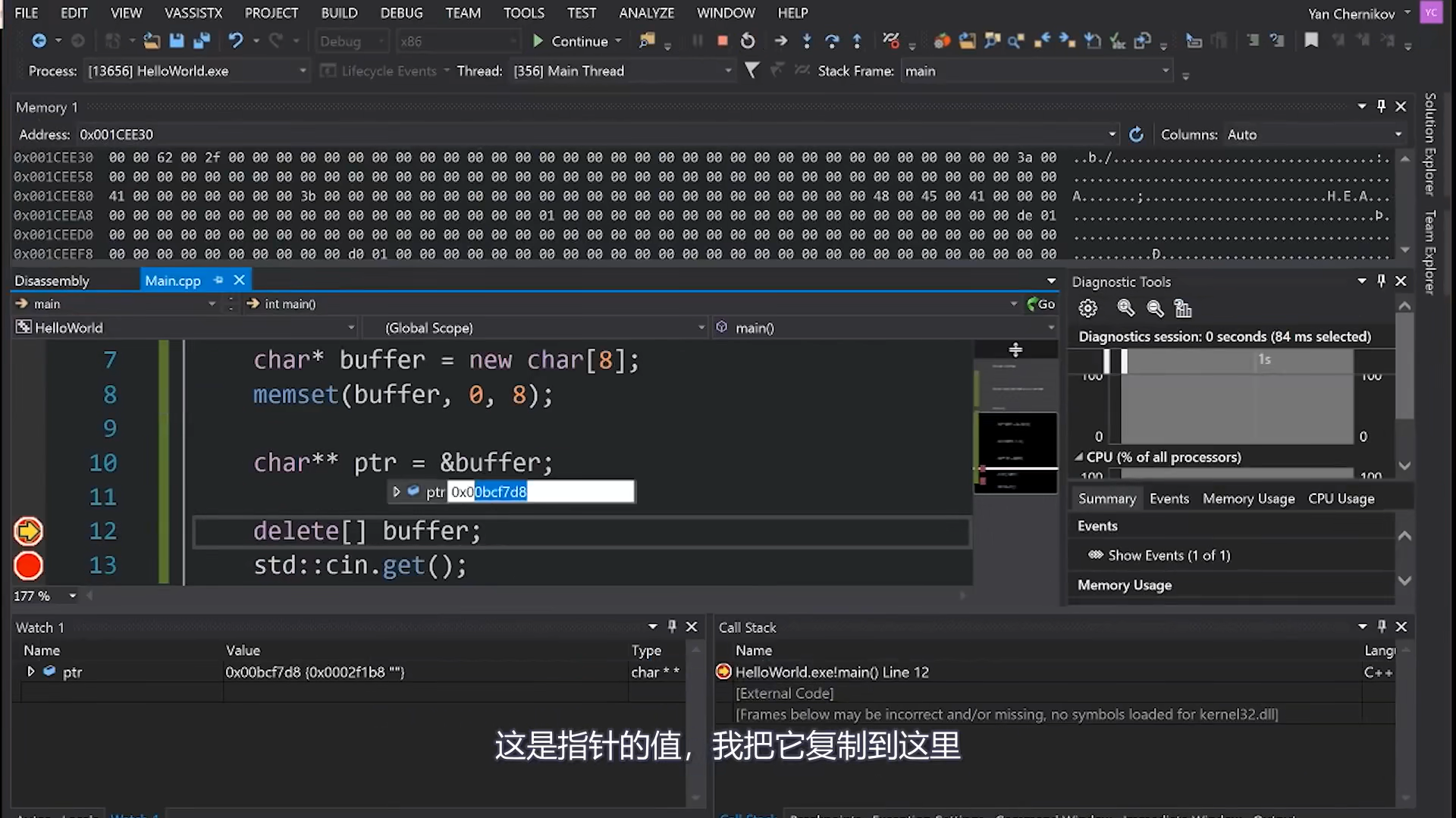
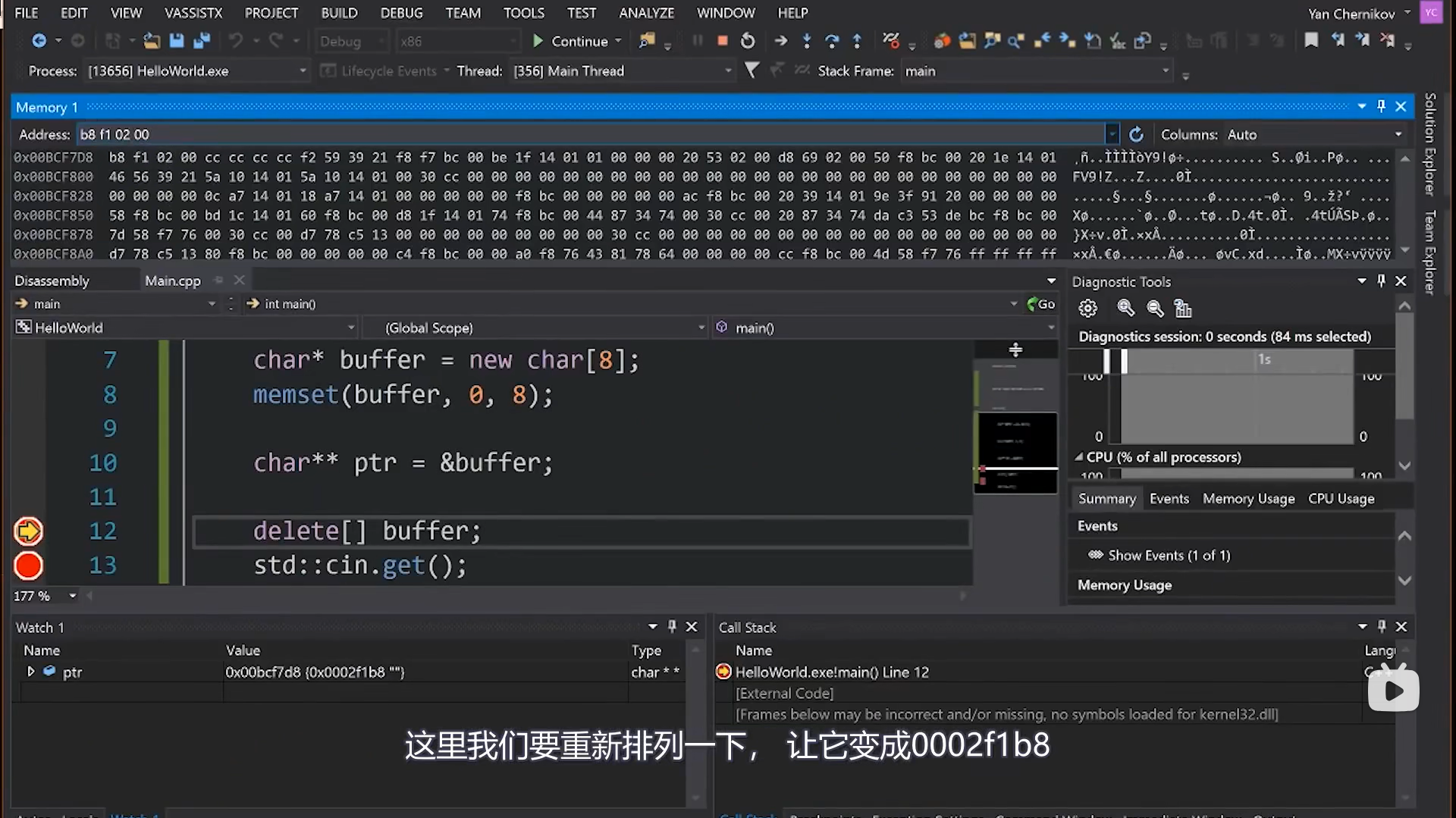
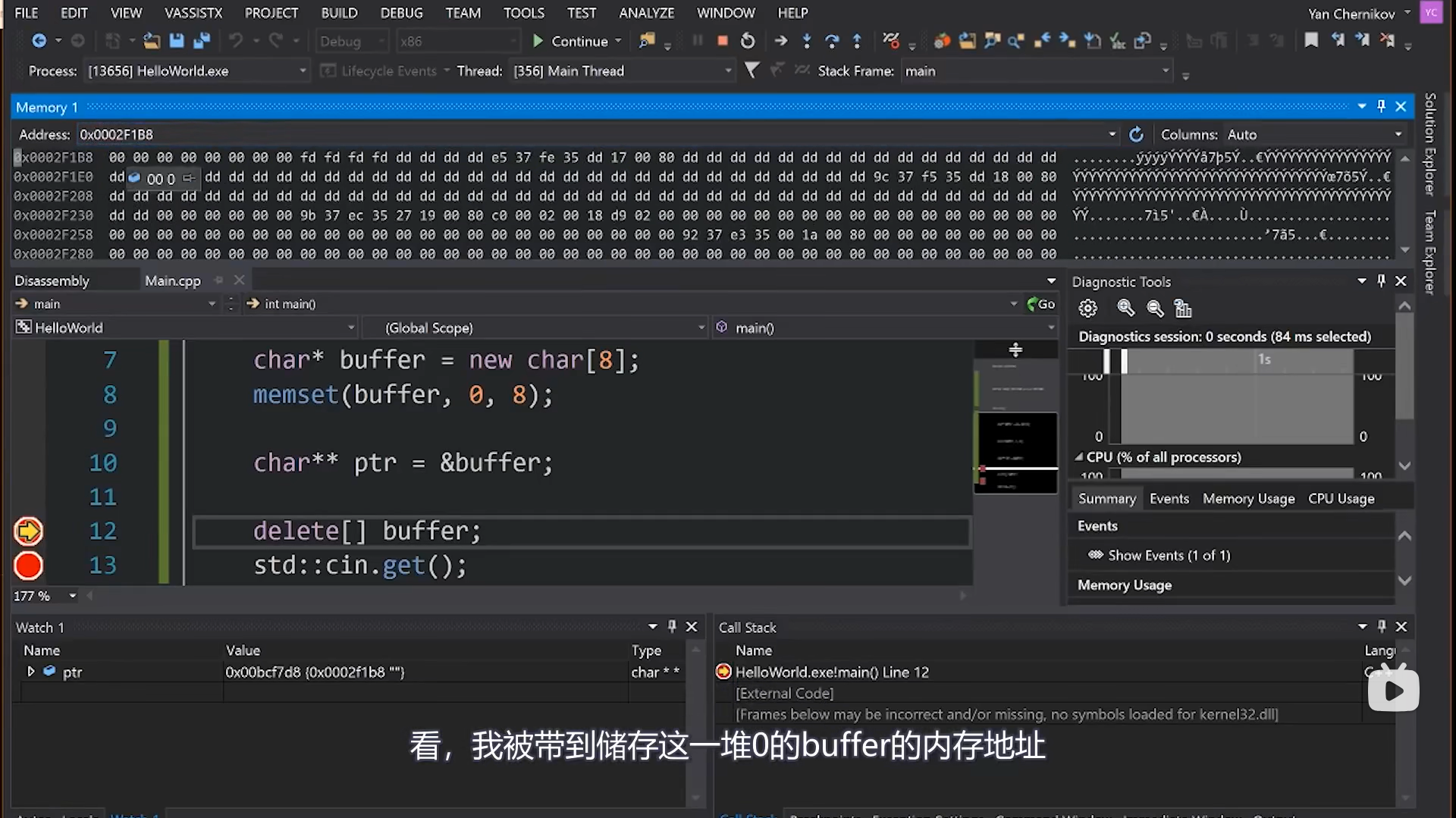
2.2 引用
引用就是给现有的变量创建别名,其本身并不是新的变量,不占用内存,没有真正的存储空间。
1 |
|
2.2.1 利用引用修改变量的值
1 | int a = 5; |
这里为变量 a 创建了一个别名 ref,ref 不是一个真正的变量,在编译之后不会得到 a 和 ref 两个变量,只会得到 a。
注意:此处的 & 是变量声明的一部分,并不是只要看见 & 就是取地址,要注意上下文。
1 |
|
可以通过修改 ref 的值来修改 a 的值。
2.2.2 引用传参
1 |
|
在调用 plus 函数时,只会将 a 的值复制到 value 中,而不会影响到真正的变量 a。
此时,就可以通过引用来传递参数,从而影响到变量 a。
1 |
|
当然,也可以使用指针来影响变量 a:
1 |
|
3 Tips
- 在 debug 时,可以在循环语句外设置一个断点,然后点击继续运行,这样就可以快速跳出循环语句继续 debug。
- 条件分支语句与内存:当我们运行程序时,整个程序及其所有模块都会加载到内存中,而在使用 if else、switch case 等条件分支语句时,会使程序跳转到内存的不同地方并从该处开始执行指令,这意味着在大量使用 if else 语句时通常会有较大的内存开销。如果想写效率更高的代码,要尽量避免使用 if else 等条件分支语句,或尝试用数学运算代替条件分支语句。
- else if 不是 C++ 中的关键字。注意,下面两个程序的输出结果是一样的。
1 |
|
1 |
|
- 在 Visual Studio 的解决方案资源管理器中的 “一堆文件夹” 不是真正的文件夹,而是过滤器,这些过滤器在磁盘上并不存在,添加或删除过滤器不会改变磁盘中实际文件夹的内容,过滤器的作用只是为了更好地组织源代码。(在过滤器目录上方的小工具栏中点击查看所有文件,即可切换到实际文件夹的目录结构,此时就可以在资源管理器中创建文件夹,而不是过滤器)
- bool 变量占 1 个 byte 的大小,而不是一个 bit。